Recently I read a thoughtful post 
at the PASS Business Analytics Conference site discussing how different the world is now for database professionals. Author Chris Webb focuses on the data science side in this post. His analysis made me think of the challenges and opportunities “big data” serves up to relational database designers.
To me these challenges are fundamental. Big Data and NoSQL bring lots of what we know about data elements, inherent data design, and data management into question. I think considering these elements closely leads to a sensible to-do list for relational database professionals.
The Data Element
One foundational relational idea is that data sets comprise discrete, atomic units of data. Data elements are not tied together in any way, two data elements may be best held in separate tables but nothing says they have to be. A data element is atomic in that it is indivisible and cannot be subdivided into parts – otherwise it is “overloaded” and therefore not truly a data element.
Many NoSQL proponents have no such scruples about atomicity. Note this excellent presentation by Eric Redmond. At about 19:40 he discusses column-oriented data stores, giving maintaining a wiki as an example. The cells shown can contain complex data forms. For example, “revision” includes at least Author and Comment. Clearly the rows and columns given in this example are quite different from relational rows and columns.
Inherent Data Structure
Another widely held premise of the relational data community is that data has a correct structure, inherent to the data itself, within context of a given business rules set. Databases should be designed according to that correct normalized structure, or at least a structure simply derivable from the normalized model. The alternative is to risk “anomalies” that force additional application code to prevent database inconsistencies that would have been avoidable in the normalized structure.
NoSQL advocates view this “design first” philosophy as an expensive and unnecessary luxury. As I’ve written in a previous post, the approach to working with Big Data seems to take a contrarian view from the perspective of the relational designer:
- “Data duplication and denormalization are first-class citizens.” (here)
- NoSQL databases “don’t have a fixed schema, allowing you to store any data in any record” (here)
- NoSQL data modeling often starts from the application-specific queries as opposed to relational modeling (here)
So for the NoSQL database designer the problem to be solved comes first, rather than the structure of the data itself.
Demise of the Relational Dream?
Since the beginning, the database community has shared a vision that all enterprise data elements would be integrated into a single database structure and accessible without duplication for any business purpose. For example, a widely used 1977 textbook cited “Elimination of Data Duplication” as a key advantage of database processing.*
Early database management systems failed to deliver on that promise, giving rise to Bill Inmon’s data warehouse architecture. Inmon’s vision aims to deliver data sharing through architecturally correct replication. Later developments like the Service Oriented Architecture (SOA) and Ralph Kimball’s dimensional paradigm adjusted but fit within the mental map that Mr. Inmon conceived. One could argue persuasively that no organization has come close to delivering on the data sharing vision, but the vision has persisted nonetheless.
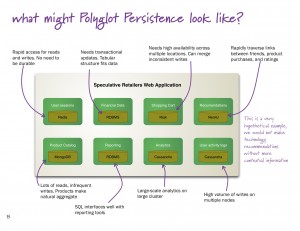
That is, until now. By adding unstructured, high volume, and high velocity data to the mix, the Big Data/NoSQL movement has effectively nullified the shared data vision without replacing it. Page 8 of Martin Fowler and Pramod Sadalage’s introductory NoSQL presentation offers a vision of Polyglot Persistence in an organization, showing coexistence of many different database paradigms for different business needs. To the seasoned relational database professional that diagram also shows data silos. The spiderweb pattern of data transfer among many independent data stores was a motivation for data sharing architectures.
Next Steps for the Database Professional
So to sum up, the NoSQL movement has rendered the data element obsolete, turned database design from an enterprise concern to an application-specific problem, and nullified the 35 year old dream of universal enterprise data sharing. Pretty depressing, right?
Not at all. I think we in the relational database world have an invigorating task list as NoSQL offerings grow to maturity in our organizations. As with any change process, step one is acknowledgment and acceptance: NoSQL is here. At some point your organization will face a business case that obviously calls for a non-relational database solution. This has likely already happened if you’re in a Fortune 1000 company.
Step two is learning. As we’ve discussed, NoSQL is different, and will be as much of a transition for SQL professionals as the transition from CODASYL databases to relational was for programmer/analysts of the 1980s.
Step three, after understanding and embracing NoSQL, is to continue where we’ve left off. While data sharing in the relational sense may have been naive, the need for enterprise data governance and architecture, data quality efforts, and effective business intelligence don’t go away with NoSQL, they just become more complex. It is time to enhance, and maybe revolutionize, our conceptual vision to encompass vast stores of unstructured data stored in unpredictable ways.
*Kroenke, David. Database Processing: Fundamentals, Modeling, Applications. Science Research Associates, Inc., 1977. p 5.