I recently listened to Brian O’Neill’s excellent interview with Tom Davenport, headlined “Why on a scale of 1-10, the field of analytics has only gone from a one to about a two in ten years time.”
The conversation covered a lot of ground as Mr O’Neill and Mr Davenport explored the reasons why. Highlights included general lack of technical literacy and lack of an organizational data driven culture. But to their credit, they took responsibility on behalf of analytics professionals, emphasizing how we in the field could change in order to make more analytics efforts successful. Rather than focusing on providing technology-centered solutions, they recommended that data and AI professionals seek first to understand and empathize with their clients or internal customers, enabling data and AI pros to develop more effective analytics capabilities in light of that understanding.
I agree that analytics professionals can improve their game. However, as a former consultant who’s switched over to the client side, I think there’s room for improvement all around. To me, clients who work proactively to prepare for an analytics project position themselves for better outcomes. Continue reading
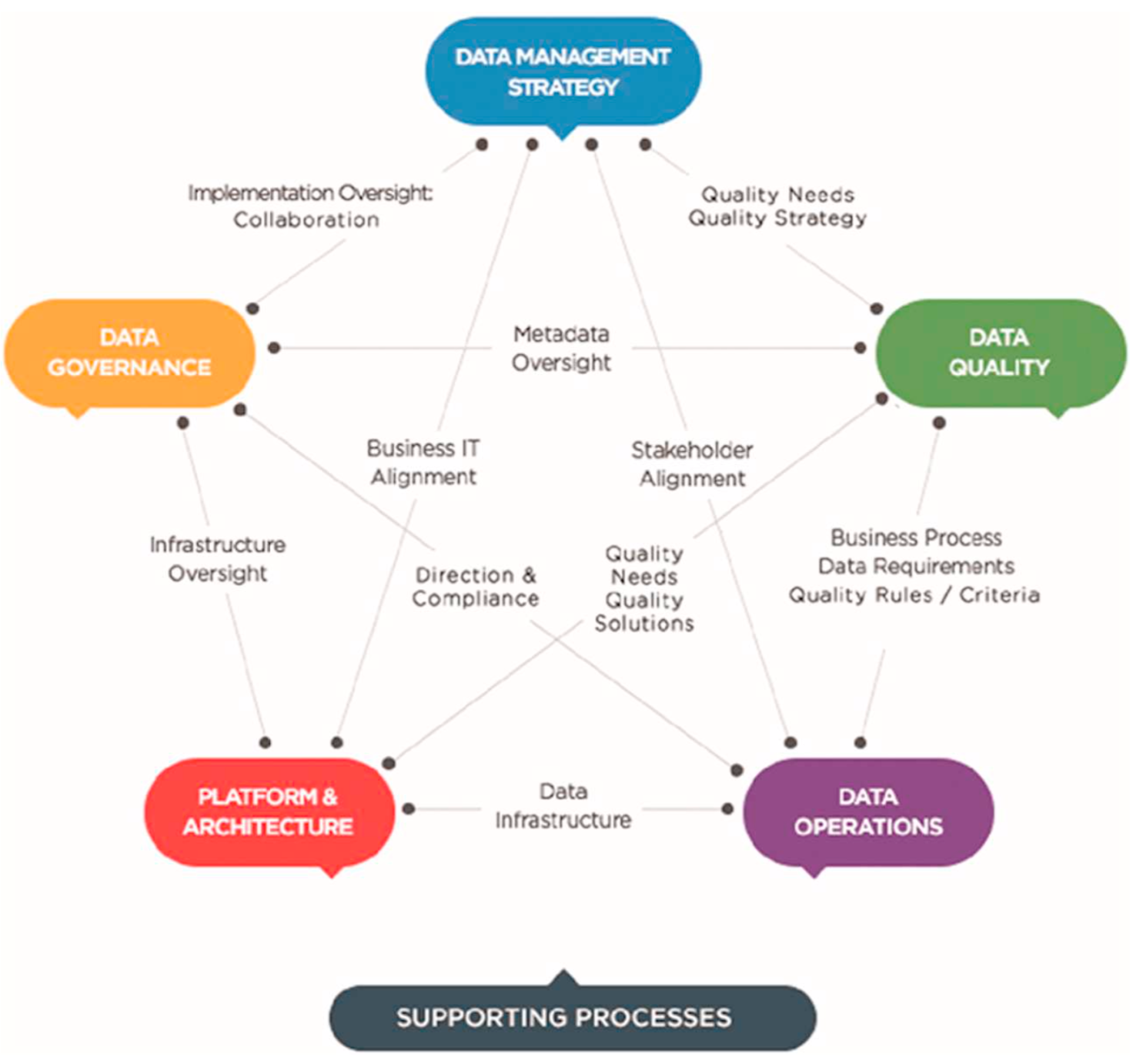
 Why pay good money for bad data?
Why pay good money for bad data?