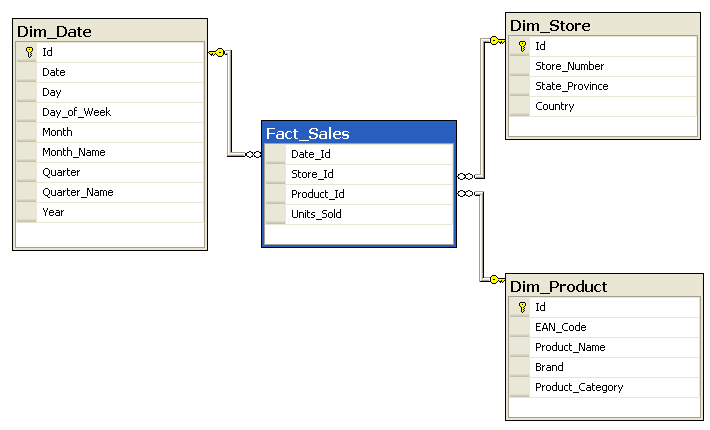
Modern data architectures, by enabling data analytics insights, promise to drive order of magnitude value gains across many business sectors (here, here, and here). Not so long ago, big data presented a daunting challenge. Although tools were plentiful, we struggled to conceptualize the architecture and organization within which to capitalize on those tools. Now solid frameworks have emerged. This post reviews two promising models for modern data architecture, and discusses two key cultural values critical to their successful adoption: drive to solve business challenges and drive for universal data correctness. Continue reading
Modern data architectures, by enabling data analytics insights, promise to drive order of magnitude value gains across many business sectors (here, here, and here). Not so long ago, big data presented a daunting challenge. Although tools were plentiful, we struggled to conceptualize the architecture and organization within which to capitalize on those tools. Now solid frameworks have emerged. This post reviews two promising models for modern data architecture, and discusses two key cultural values critical to their successful adoption: drive to solve business challenges and drive for universal data correctness. Continue reading
Sound Data Culture Enables Modern Data Architectures
Leave a reply
 Tableau desktop (10.2.2 on Windows 7 at work) was consistently locking up my computer or causing a
Tableau desktop (10.2.2 on Windows 7 at work) was consistently locking up my computer or causing a  A year ago I
A year ago I