The data integration process is traditionally thought of in three steps: extract, transform, and load (ETL). Putting aside the often-discussed order of their execution,  “extract” is pulling data out of a source system, “transform” means validating the source data and converting it to the desired standard (e.g. yards to meters), and load means storing the data at the destination.
“extract” is pulling data out of a source system, “transform” means validating the source data and converting it to the desired standard (e.g. yards to meters), and load means storing the data at the destination.
An additional step, data “enrichment”, has recently emerged, offering significant improvement in business value of integrated data. Applying it effectively requires a foundation of sound data management practices. Continue reading

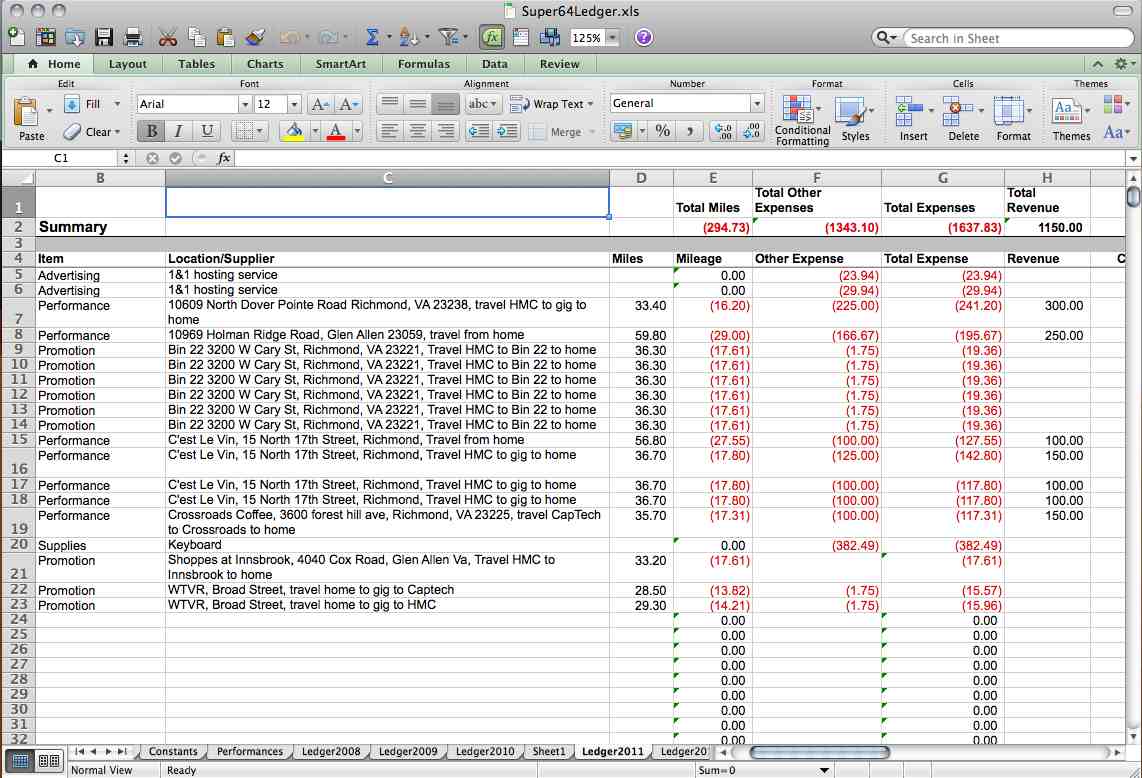
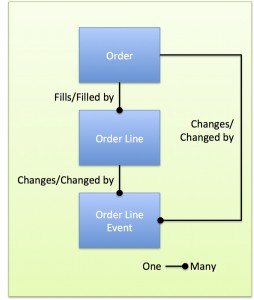 As important as it is, data modeling has always had a geeky, faintly impractical tinge to some. I’ve seen application development projects proceed with a suboptimal, “good enough”, model. The resulting systems might otherwise be well-architected, but sometimes strange vulnerabilities emerge that track directly to data design flaws.
As important as it is, data modeling has always had a geeky, faintly impractical tinge to some. I’ve seen application development projects proceed with a suboptimal, “good enough”, model. The resulting systems might otherwise be well-architected, but sometimes strange vulnerabilities emerge that track directly to data design flaws.