 At the very first TDWI Conference, Duane Hufford described a phenomenon he called “embedded data”, now more commonly called “overloaded data”, where two or more concepts are stuffed into a single data field (“Metadata Repositories,” TDWI Conference 1995). He described and portrayed in graphics three types of overloaded data. Almost 20 years later, overloaded data remains rampant but Mr Hufford’s ideas, presented below with updated examples, are unfortunately not widely discussed.
At the very first TDWI Conference, Duane Hufford described a phenomenon he called “embedded data”, now more commonly called “overloaded data”, where two or more concepts are stuffed into a single data field (“Metadata Repositories,” TDWI Conference 1995). He described and portrayed in graphics three types of overloaded data. Almost 20 years later, overloaded data remains rampant but Mr Hufford’s ideas, presented below with updated examples, are unfortunately not widely discussed.
[Note: in March of 2021 I added one further category, bundling. – BL]
Overloaded data breeds in areas not exposed to sound data management techniques for one reason or the other. Big data acquisition typically loads data uncleansed, shifting the burden of unpacking overloaded fields to the receiver (pity the poor data scientist spending 70% of her time acquiring and cleaning data!)
One might refer to non-overloaded data as “atomic”. Beyond making data harder to use, overloaded data requires more code to manage than atomic data (see why in the sections below) so by extension it increases IT costs.
Here’s a field guide to three different types of overloaded data, associated risks, and how to avoid them:
Chaining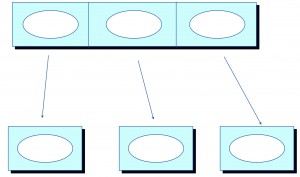
Definition: In the case of Chaining, a field contains separate concepts concatenated together in specific character zones.
Example from the wild: You likely have examples of  chaining in your wallet. Perhaps the most common instance of chaining is the credit card number, described here and illustrated at right. As shown, a 16 digit card number contains specific zones for four different data elements.
chaining in your wallet. Perhaps the most common instance of chaining is the credit card number, described here and illustrated at right. As shown, a 16 digit card number contains specific zones for four different data elements.
Impacts:
- Chained data elements cannot be referenced without parsing the contents of the field, so the developer or data analyst must know the format of the chained field and the operations required to separate the different data elements.
- Fixed length chaining schemes are limited by space available, so there’s always a possibility that the count of represented objects exceeds capacity. For example, the credit card number scheme shown breaks down when more than 99999 banks issue credit cards, assuming numeric format.
Eradication and prevention: Systems bringing chained fields into their database should parse and save each chained element separately. Typically, fields like credit card number must be retained as account numbers, so the original chained field will often also be included. If the database must contain only the chained field, then use shared modules or database views to present the component pieces so that those accessing the data don’t need to.
Coupling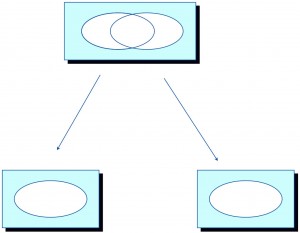
Definition: When two or more data elements are coupled into one field, they combine in a less explicit way than in the case of chaining. In one typical case, a code table embeds multiple ideas into one set of codes (see example below). Another common example is when the field name itself contains a separate concept that describes the data element, as in the case of a “FederalTaxAmount” field, where the name embeds the tax type describing the tax amount value.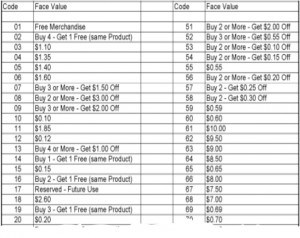
Example from the wild: Coupling is widespread in many business applications. For example, this list of UPC coupon value codes shows several different concepts stuffed into a single two digit number: discount amount, how many items you have to buy to get the discount, and if coupon is for full product value.
Impacts
- As with all overloaded data, in order to use any one of the embedded concepts the data analyst must understand how the concepts are combined and how to parse them. Here to use the data element “quantity that must be purchased to get a discount” the analyst must parse each of the 100 values then record the result either in program code or in a separate table.
- Multi-concept codes like this one prevent use of mnemonics, where the code provides a hint to its meaning. For example, standard state codes (AL for Alabama, etc) provide a mental shortcut to the state name. If a code combined states, regions, and counties, then it wouldn’t be obvious whether AL were Alabama or Alameda County.
Eradication and prevention: Again, systems bringing coupled fields into their database should parse and save each element separately, and where these fields must be used they should be unpacked and presented by shared modules if possible. In my experience coupled code values often result from application maintenance teams not being able to keep up with requested business changes. Often the business jams two concepts into the same code value, especially when they control code definition tables. Data practices education for business folks and faster turnaround on maintenance requests can help.
Multipurpose Fields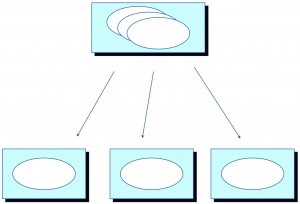
Definition: In multipurpose fields, a field changes identity from one data element to another in different contexts. For example, once I reviewed a database where one column represented either the name of the horse or the age of the nurse, depending on which product the table’s row represented.
Example from the wild: Multipurpose fields are less common than chained or coupled fields, and tend to be visible only to developers, but still examples abound. At this link a well intentioned developer asks:
A
Loadcan have a value forDistancewhich is some integer value OR it can have aPositionindicated [by] a panel point “P1”, “P2”, “P3”. Question: Should I have two nullable fields or a single field that I just parse to see if it is an integer or not? If it is an integer I know it’s a distance value, if not, it’s a position value. Are there advantages to both?
Luckily the response there is helpful and correct in pointing out that the multipurpose option will require significantly more code to implement.
Impacts
- In order to use multipurpose fields the data analyst must understand what the field means in different contexts, and how to identify which context is which. For example, how can the analyst tell whether the product applies to a horse or a nurse? After figuring that out the analyst must write code to parse out the rows correctly.
- Multipurpose fields tend to indicate poor overall system design. In a well designed system each module handles only one function. If one module processes rows containing one or more multipurpose fields, then that module may be more maintainable if it were split into two. Why should nurse processing be affected when horse processing needs a maintenance fix?
Eradication and prevention: As always, systems bringing multivalued fields across interfaces from other systems should separate the different concepts into different data elements. Multivalued fields often result from naive data management or system design techniques. Less experienced designers can overvalue the gain of saving “disk space” relative to the negative impacts of extra code and maintenance cost. So education in program design and data management helps, as does leveraging expertise of senior developers in design reviews.
Bundling
Definition: Bundled data is a situation where a single column in a table contains an array of values.
 Examples from the wild: A colleague of mine working on a reporting assignment found a list of file names in a single varchar column in a system that tracks file transfers. A quick web search for “sql column contains an array” returns many examples and how-to instructions. Arrays are a valid type in Google Big Query and Spark SQL. This construction will likely become more common as more companies adopt modern database technology and associated methods.
Examples from the wild: A colleague of mine working on a reporting assignment found a list of file names in a single varchar column in a system that tracks file transfers. A quick web search for “sql column contains an array” returns many examples and how-to instructions. Arrays are a valid type in Google Big Query and Spark SQL. This construction will likely become more common as more companies adopt modern database technology and associated methods.
Impacts:
- Bundled data requires programming to unpack. For example, in our case we wanted to report on individual file status in Tableau. Tableau didn’t have processing tools to easily separate the bundled file names, so we had to request an extract table that divided the values into separate rows.
- If bundling becomes widespread in operational systems, reporting from these databases will require extract operations to divide bundled columns into separate rows, increasing development costs and maintenance overhead unless those unbundling operations are integrated into database management systems that support array datatypes.
Eradication and prevention: Organizations can reduce the impact of bundled columns by including stakeholders who require relational data in system design. Rather than leaving interface and reporting requirements to the end, and tacking on reporting functionality after completion of core components, thinking early about outbound data flows and data presentation can ensure techniques like bundling are limited to areas where they will have less impact.
Pingback: Selected data modeling best practices | Bob Lambert
Pingback: Leadership Must Prioritize Data Quality | Bob Lambert
Pingback: One More Species of Overloaded Data | Bob Lambert