 I recently found myself in a series of conversations in which I needed to make a case for dimensional data modeling. The discussions involved a group of highly skilled data architects who were surely familiar with dimensional techniques but didn’t see them as the best solution in the case at hand.
I recently found myself in a series of conversations in which I needed to make a case for dimensional data modeling. The discussions involved a group of highly skilled data architects who were surely familiar with dimensional techniques but didn’t see them as the best solution in the case at hand.
I thought it would be easy to find a quick, jargon free summary of best reporting database design principles aimed at a technical audience. There were a number of good summaries (cited at the end of this post), but none pitched just right for this highly-technical-but-outside-the-data-warehouse-world crowd.
I wanted to raise the dimensional model because, for most business reporting scenarios, it not only delivers on reporting needs, but also helps report developers handle changes to those needs as a side effect of the design.
So these are the notes I prepared for the conversation. They helped us all get on the same page, hopefully they will be useful to others:
Reporting Design Values
A reporting database should meet these non-functional requirements:
- Flexibility: quickly deliver on requirements changes as users demand new reporting data, different metrics, additional reference data, and changes in level of report detail
- Simplicity: make report SQL as simple as possible
- Reliability: data for reporting is available in a timely manner and is consistent with operational sources
- Security: users have access only to data they need
Here’s a brief description of dimensional database design followed by an explanation of how it delivers on the non-functionals above:
The Dimensional Model:
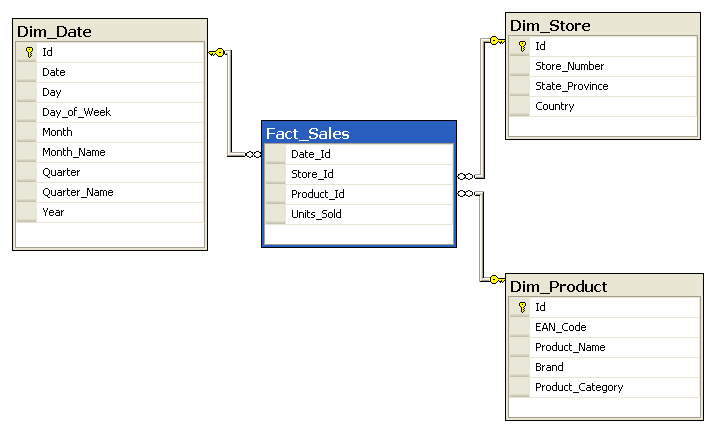
Generally, the pattern of a dimensional model is a “fact” table surrounded by several “dimension” tables.
- If there are many fact tables in a model, then each is a child in a foreign key relationship with many dimension tables, and a single dimension table may have one to many relationships with many fact tables.
- Generally speaking, a fact table is never directly related to another fact, and a dimension never related to another dimension.
A fact table may describe an event or transaction, like a store purchase, or it may represent the current status of a business element that can be described across many dimensions. For example, a patient in a hospital at a given time with a medical condition who is attended by a medical professional.
The fact table consists of
- Foreign keys to dimension tables, like customer, location, date/time, order number, product id, etc.
- Numeric measures describing the intersection of all of the foreign keys. For example order quantity, extended price, or patient age.
- Preferably, fact columns are “additive” in that they can be aggregated using simple functions. For example, one could simply add individual salaries to derive total payroll spend, or average them to obtain average compensation.
- Fact tables tend to have many rows, and therefore designers apply strategies to maximize performance:
- Reduce table width as much as possible by minimizing alphanumeric columns. Use of surrogate primary keys defined as integers is widespread in dimensional databases.
- Apply database optimization techniques like partitioning and advanced indexing
Each row of a dimension table represents the lowest relevant level of detail for a given business concern. A location dimension table might include one row for each section of a store at a given address, in a city, in a state, in a region, in a country.
While fact tables tend to have as few alphanumeric columns as possible due to their many rows, dimension tables can often be rich in descriptive information having relatively few rows.
For large dimension tables, like claims, orders, etc., designers optimize performance by using some of the strategies used for fact tables. As a last resort, designers may normalize large dimension tables so that more general queries can access smaller sets.
How does the Dimensional Model support the non-functional requirements?
- Flexibility: quickly deliver on requirements changes as users demand new reporting data, different metrics, different reference data, and changes in level of report detail
- If a new requirement requires new measures, new dimensions, or new data describing an existing dimension, database designers can add new measures, dimensions, or dimension columns without changing existing report sql
- If the fact table is at the lowest relevant level of detail, relatively simple SQL changes can provide more or less detail or modify measures or dimensions in a report.
- Simplicity: make report SQL as simple as possible
- In the dimensional model, all joins are one fact to one dimension. There is no traversal of multiple tables to get to a needed column. (Unless a very large dimension table has been normalized to improve query response)
- Not all fact measures are additive, but designing toward additive facts whenever possible reduces the need for the complex math or conditional aggregations often required in a normalized or unnormalized design.
- I’ve seen reporting databases designed in a way that allows different measures to occupy the same column, with a separate code column identifying which definition applies to each row. This is a form of embedded data, which requires additional SQL code to unpack the contents of a given row. In the dimensional model, all columns are explicit rather than abstract, there are no context-dependent meanings to code around.
- Reliability: data for reporting is available in a timely manner and is consistent with operational sources
- Of course data load depends on volume of data and design of the ETL stream, but dimensional load patterns are standard practice, with standard components for fact and dimension loads built in to all major ETL packages.
- Assuming history is maintained in source systems, fact and dim tables should be designed to be totally reloadable from operational sources. If facts and large dims are partitioned, reloads can execute one partition at a time.
- Security: users have access only to data they need
- Consolidating subject area data into a relatively small set of tables facilitates restricting access by data content. For example, database views can be defined such that users in each department might be restricted to only see their department’s data, or only a very small set of users might have access to patient health claims.
We’ve reviewed the dimensional model based on key reporting database design values. There are many other aspects of the dimensional model to consider, and of course much complexity to the technique in practice.
Below are a few other sources that may be useful in learning and applying dimensional modeling. Please feel free to add further resources in the comments section below.
- https://en.wikipedia.org/wiki/Dimensional_modeling: Yes, the wikipedia page provides a concise definition and brief “how to” for aspiring dimensional modelers
- Ralph Kimball’s Books: Ralph Kimball is known as the inventor of the dimensional technique. This links to his latest compilation, highly recommended as a first in-depth read for new designers and as a reference for anyone in the field.
- https://dwbi.org/data-modelling/dimensional-model/1-dimensional-modeling-guide: another overview and step by step guide
- http://www.uniriotec.br/~tanaka/SAIN/03-TheProblemWithDimensionalModeling-Inmon-DMReview-2000.pdf: for those looking for a contrarian take, this article from Bill Inmon, “the father of data warehousing,” raises valid concerns that must be taken into account. My view: dimensional modeling is the right design within a single reporting context (one application, one department, and so on). Larger and more varied contexts require thoughtful designs that might include dimensional elements in addition to other techniques.
5 responses to “Reporting Database Design Guidelines: Dimensional Values and Strategies”
[…] developer, DBAs and data architects please offer comments if I mischaracterize. Another note: a well designed dimensional datamart goes a long way to preventing poorly formed queries that overuse resources. This post is for the […]
[…] for Tableau teams supporting enterprise analytics and reporting is to draw data from a well curated dimensional database. With that architecture, CVI would be a column in the Customer dimension table, and a CVI […]
You are awesome! Can I cite you in a paper I am writing?❤️
Thank you! Of course you may cite me, along with the appropriate footnote of course 🙂
[…] is to do that work at the database level. As the webinar details, Tableau performs best against dimensional star or snowflake database designs. Relational database management systems (DMBS) like SQL Server, […]