“At least 84 percent of consumers across all industries say their experiences using digital tools and services fall short of expectations.”* That quote headed a recent article by David Roe on the role of data integration in digital workplace apps. However, the opening quote reflects the pervasive dearth of integrated data among the companies most of us frequent.
“At least 84 percent of consumers across all industries say their experiences using digital tools and services fall short of expectations.”* That quote headed a recent article by David Roe on the role of data integration in digital workplace apps. However, the opening quote reflects the pervasive dearth of integrated data among the companies most of us frequent.
We’ve all experienced the effects. Last week I was in a fender bender. Due to a mixup I didn’t have my insurance card with me, so I called the insurance company to get the info. They had no record of me associated with my car. It turned out that my car is insured under my wife’s name, hers under mine. Although I’ve been their customer for 25 years, and was driving my own car, they couldn’t give me insurance info. Sure, they were following good security practices. But I’m not letting them off the hook. Continue reading
 To me, development projects fail or succeed in the first few
To me, development projects fail or succeed in the first few 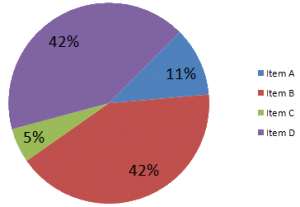

 A year ago I
A year ago I