Also see the related post More on “Select Failed. [2646] No more spool space”
 If you are a SQL developer or data analyst working with Teradata, it is likely you’ve gotten this error message: “Select Failed. [2646] No more spool space”. Roughly speaking, Teradata “spool” is the space DBAs assign to each user account as work space for queries. So, for example, if your query needs to build an intermediate table behind the scenes to sort or otherwise process before it hands over your result set, that happens in spool space. It is limited, in part, to keep your potentially runaway query from using up too much space and clogging up the system.
If you are a SQL developer or data analyst working with Teradata, it is likely you’ve gotten this error message: “Select Failed. [2646] No more spool space”. Roughly speaking, Teradata “spool” is the space DBAs assign to each user account as work space for queries. So, for example, if your query needs to build an intermediate table behind the scenes to sort or otherwise process before it hands over your result set, that happens in spool space. It is limited, in part, to keep your potentially runaway query from using up too much space and clogging up the system.
After briefly setting the stage, this post presents the top three tactics I use to avoid or overcome spool space errors. For the second two tactics I’ll show working code. At the end of the post you’ll find volatile DDL that you can use to get the queries to run. Continue reading
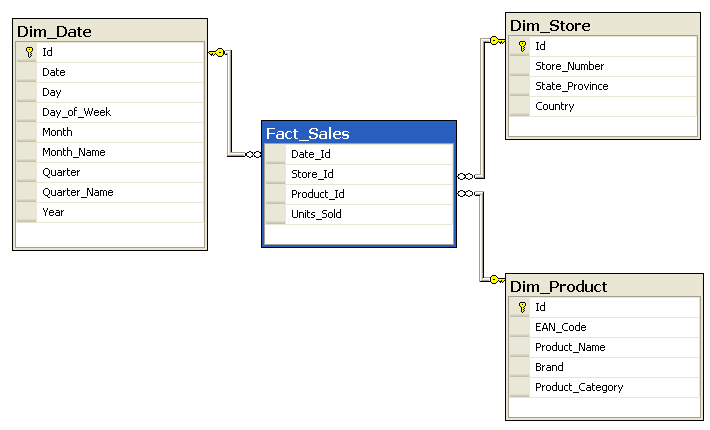




 ta science or warehousing context, which is often where quality problems
ta science or warehousing context, which is often where quality problems  Yesterday I had the pleasure of presenting “The Business End of Data Modeling” for the Lynchburg SQL Server User’s Group. It was a great time, thanks for having me out!
Yesterday I had the pleasure of presenting “The Business End of Data Modeling” for the Lynchburg SQL Server User’s Group. It was a great time, thanks for having me out!